模型架构图
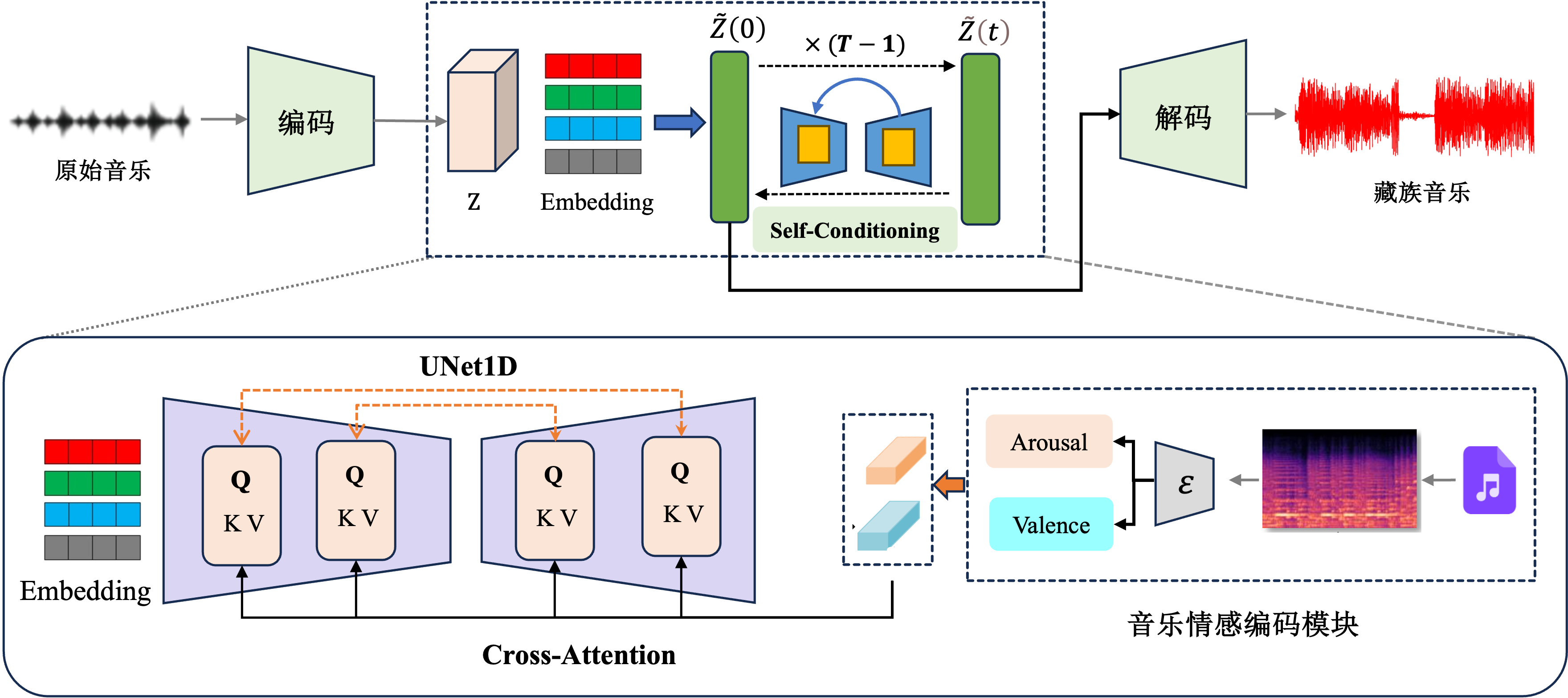
人工智能技术在音乐创作领域取得了显著进展,但针对藏族音乐自动生成的研究仍相对匮乏。现有研究在藏族音乐生成中主要面临三个挑战:缺乏特定情感的表达能力、高维特征处理效率低下,以及音乐上下文一致性不足。为解决上述问题,提出一种基于情感引导的扩散模型(Emotion-Driven Diffusion Model, EDDM),该模型基于VAE-Diffusion框架,利用变分自编码器提取音源数据关键潜在特征,并在扩散过程中对其进行建模。首先,设计情感特征编码器以提取音乐情感特征,并通过交叉注意力机制将情感特征嵌入到扩散模型中,实现藏族音乐特定情感和风格的精准表达;其次,引入Token Drop策略过滤冗余特征,提高音乐生成的鲁棒性和多样化;最后,提出Self-Conditioning机制增强上下文关联,利用上一步信息来指导下一步结果生成,确保音乐生成的一致性。实验结果表明,EDDM在藏族音乐生成任务上效果突出,在客观评价方面,模型在FAD(2.35↓)、JSD(0.08↓)、NDB(18↑)等指标上均优于现有方法;主观评价中,生成的音乐展现出良好的情感表达能力和音乐特征一致性。EDDM在民族音乐自动生成领域具有一定的创新性和应用价值。
情感唤醒: 2.0 | 情感价值: 7.0
情感唤醒: 7.5 | 情感价值: 8.5
情感唤醒: 3.0 | 情感价值: 4.5
情感唤醒: 5.0 | 情感价值: 6.0
情感唤醒: 8.0 | 情感价值: 7.0